Creo que en las personas está muy arraigado el concepto de riesgo. Lo entendemos intuitivamente: hablamos de deportes de riesgo como el ciclismo de montaña o escalada free solo (sin cuerda), en que si te caes te va a doler. Entendemos que corremos un riesgo al cambiarnos de trabajo, porque no sabemos realmente si nos va a ir bien. Incluso entendemos que corremos riesgo al probar una nueva comida, porque puede no gustarnos o incluso podemos ser alérgicos.
Pero toda esta intuición no es tan simple de llevar a medidas que nos permitan comparar cuándo estamos corriendo más riesgo.
En este artículo te explicaré cómo esta intuición de riesgo se puede plasmar en el mundo financiero, viendo los pro y contras de las medidas de riesgo más tradicionales y las que usamos en Fintual.
Primero, notemos que en los casos anteriores siempre había algo desconocido. Por ejemplo, para el caso del ciclismo de montaña no sabes cuándo ni cómo te vas a caer. En el caso de las inversiones es parecido. En el momento en que uno hace una inversión en un activo, ese activo puede bajar a un precio menor que el de compra, lo que nos haría tener una rentabilidad negativa. Esta rentabilidad se puede modelar como una variable aleatoria donde para cualquier día t la rentabilidad diaria se escribe como:
$$r_{t}=\frac{p_{t}+FC_{t}-p_{t-1}}{p_{t-1}},$$
donde \( p_{t} \) es el precio en el día \( {t} \) y \( FC_{t} \) son los flujos de caja. Por ejemplo la distribución de la rentabilidad diaria del índice S&P500 se ve así

Y es sobre estas distribuciones de rentabilidades que queremos estimar el riesgo a la hora de decidir en qué activos invertir
Los pros y contras de la varianza como una medición de riesgo
En un gráfico como el anterior, mientras más ancha sea la distribución, más posibilidades hay de que nuestra rentabilidad sea negativa. Inspirado en esta intuición, Harry Markowitz planteó en su trabajo Portfolio Selection (1952) que la varianza de la distribución es una manera efectiva de medir el riesgo: mientras mayor la varianza de dicha distribución, mayor el nivel de riesgo.
Lo que queremos es saber el riesgo futuro de los retornos del S&P, medido a través de la varianza. Pero como todavía no podemos viajar al futuro, podemos usar una muestra del pasado. La varianza en esa muestra se aproximará a la varianza de los datos reales.
A esto podemos sumar lo que Benoit Mandelbrot en su paper de 1967 titulado The Variation of Some Other Speculative Prices planteó: que existen clusters de volatilidad. Eso es, que “grandes cambios tienden a ser seguidos por grandes cambios -de cualquier signo- y pequeños cambios tienden a ser seguidos por pequeños cambios”.
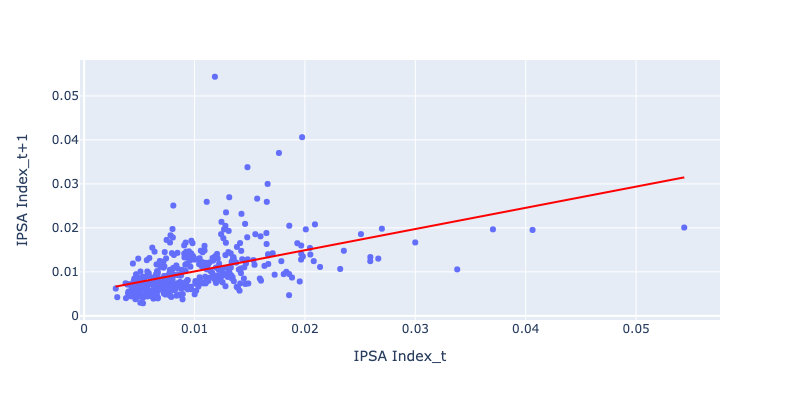
Así, la varianza ex post es un buen predictor de la varianza ex ante. Esto se puede ver en los siguientes gráficos, donde se muestra la varianza de las rentabilidades mensuales del mes t (eje X) versus el mes t+1 (eje Y) para distintos índices.


Pero usar la varianza como medida de riesgo tiene una desventaja bien importante, que considera una pérdida de cierta magnitud igual de riesgosa que una ganancia de la misma magnitud.
Más gráficamente, esa medida de riesgo considera que estas dos distribuciones de retornos son igual de riesgosas:

Aunque, según la definición de riesgo planteada por Markowitz, estas distribuciones son igual de riesgosas, cualquier persona evaluaría que la distribución roja es menos "riesgosa" puesto que la probabilidad de tener retornos negativos es mucho menor.
Por otro lado, supongamos que tenemos dos portafolios: el portafolio 1 invierte la mitad de mi dinero en un activo riesgoso, por ejemplo, S&P500; y la otra en un activo libre de riesgo. El portafolio 2 invierte todo en el S&P500.
De las propiedades de la varianza sabemos que para una distribución aleatoria \( Y \) y una constante \( a\) tenemos que $$\text{var}(aY)=a^2\text{var}(Y)$$
entonces el riesgo del portafolio 2 es 4 veces el riesgo del portafolio 1, lo que parece contraintuitivo puesto que solo invertí dos veces más en el mismo activo.
Las medidas de riesgo coherentes
Para quitar estos problemas, queremos que nuestra forma de medir el riesgo crezca de forma lineal en la medida que nos exponemos más a un activo y que además si la distribución es siempre mayor a otra, esta última debería ser más riesgosa. Si agregamos que necesitamos el principio de diversificación y el hecho de que agregar un activo libre de riesgo a nuestro portfolio debe disminuir el riesgo, obtenemos las:

Estas propiedades fueron propuestas matemáticamente por Artzner en su paper Coherent Measure of Risk, de 1999:
sea \( \rho \) una medida de riesgo y \( X \) (y \( X_i \)) distribuciones de retornos,
-
Invarianza a la traslación: sea \( R \) un activo con un retorno garantizado \( \alpha \) entonces \( \rho(X+R) = \rho(X) - \alpha \) lo que significa que un activo garantizado te disminuye el riesgo.
-
Subaditividad: para todo \( X_1 \) y \( X_2 \) se tiene \( \rho(X_1 + X_2) \leq \rho(X_1) + \rho(X_2) \), lo cual se traduciría en el principio de diversificación usado en inversiones (no pongas todos los huevos en la misma canasta).
-
Positive homogeneity: para todo \( \lambda \geq 0 \) se tiene \( \rho(\lambda X) = \lambda \rho(X) \), esto establece que el riesgo de una posición incrementa linealmente con la exposición.
-
Monotonicidad: para todo \( X_1 \) y \( X_2 \) tal que \( X_1 \leq X_2 \), entonces \( \rho(X_2) \leq \rho(X_1) \). Dado que \( X_1 \) y \( X_2 \) son variables aleatorias, la restricción \( X_1 \leq X_2 \) es en el sentido de dominancia estocástica de segundo orden. Para que esto se cumpla es suficiente que, para cualquier valor t, la probabilidad de que \( X_1 \) sea menor a t es menor a la probabilidad de que \( X_2 \) sea menor a t, lo cual puesto en ecuaciones se veria asi \( \mathbb{P}[X_1\leq t]\leq \mathbb{P}[X_2\leq t] \). Así, la monotonicidad significa que si una distribución es siempre menor o igual que otra esta deberá ser más riesgosa.
Qué es el CVAR: los pro y contras
Una de las medidas de riesgo coherente más conocidas es el Conditional Value at Risk o CVaR. Este se define por:
$$CVaR_{\alpha}(X) = \frac{1}{\alpha} \int_{0}^{\alpha} VaR_{\gamma}(X)d\gamma$$
Donde:
$$ VaR_{\alpha}(X) = -\inf \left\lbrace x \in \mathbb{R} : F_X(x)>\alpha \right \rbrace $$
\(F_X(x)\) es la probabilidad de no exceder el valor \( x \). El \( VaR_\alpha \) es el quantil \( \alpha \) de la distribución y el CVaR es el valor esperado de todos los valores por debajo de \( VaR_\alpha \), entonces el CVaR no es más que el promedio en alguna cola de la distribución. Para nuestras distribuciones anteriores los CVaR serían:
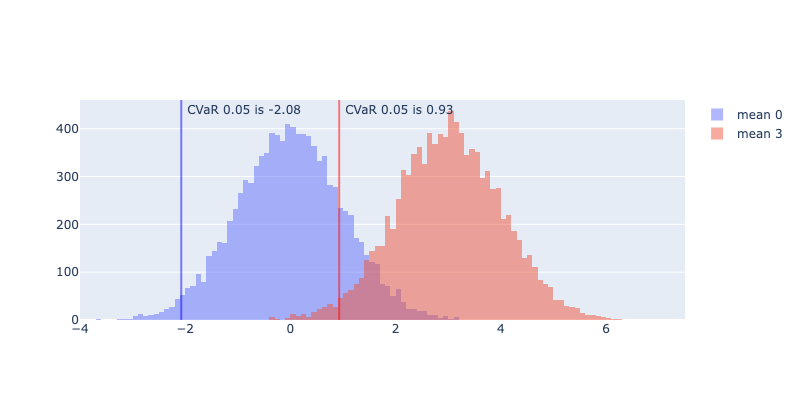
Al ser una medida coherente el CVaR no tiene los problemas de la varianza. Además, en su paper Optimization of Conditional Value-at-Risk publicado en el 2000, Rockafellar y Uryasev muestran que el CVaR se puede representar como un problema de optimización lineal. Esto lo hace muy útil en problemas de optimización de portafolios como los que usamos en Fintual. (si quieres ver más detalles mira acá).
Pero el CVAR tiene una desventaja: se necesitan más datos; más historia. Es una medición de cola de la distribución, que por definición son sucesos que no ocurren tan a menudo.
Comparaciones numéricas de riesgo con varianza y CVaR
Hasta ahora hemos hablado de propiedades teóricas, pero ¿qué pasa si incorporamos números?
Compararemos los histogramas de dos distribuciones: una Normal con una distribución de Gumbel. Sus gráficos se ven más o menos así
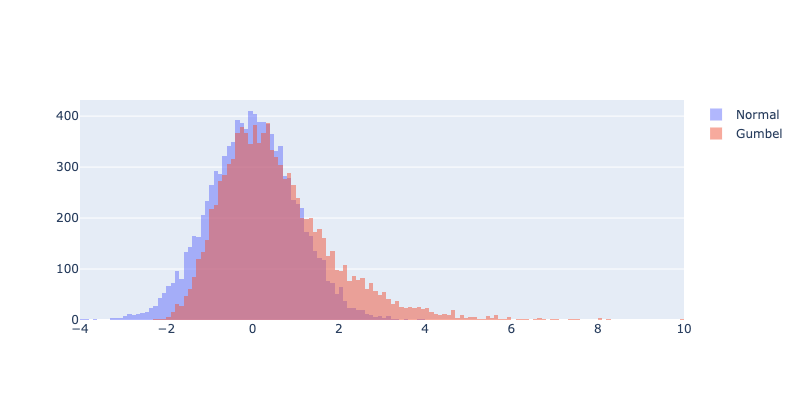
Mirando estas dos distribuciones probablemente opines que la distribución de Gumbel es la menos riesgosa, dado que la probabilidad de perder es menor que en la Normal: (su área a la izquierda del 0 es menor). Por otro lado, su cola a la derecha del 0 es más larga.
Ahora, si evaluamos ambas mediciones de riesgo veremos que:
La varianza muestral de la distribución de Gumbel es 1.64 y la de la Normal 1.01

Esto va en contra de nuestra intuición.
Pero el CVaR muestral de la distribución de Gumbel es -1.39 y el de la Normal -2.07. Este último sí es capaz de capturar nuestra intuición.
Conclusión
Como podemos ver, el riesgo proviene del desconocimiento de eventos futuros y medirlo puede ser una tarea compleja. En el área financiera, los primeros pasos para entender el riesgo a través de la varianza conducían a conclusiones contraintuitivas, como el aumento cuadrático del riesgo cuando se aumenta la exposición a un instrumento. Una forma de evitar este tipo de problemas fue definir cuáles son las características que la medición de riesgo tiene que cumplir. Con esto surgió el CVaR que es capaz de acercarse más a nuestra intuición de riesgo.
Entonces, ¿por qué elegimos CVaR como nuestra medida de riesgo en Fintual? porque es monotónico, tiene homogeneidad positiva, puede escribirse como un problema de optimización lineal y es usado ampliamente en la literatura especializada.
¿Quieres saber cómo hicimos estos experimentos? sigue este link a Colab