La IA cambió el mundo. Además de los usos en las empresas, piensa en las millones de interacciones menos glamorosas o publicitadas, desde reconocimiento de voz (“Alexa, pon música country pop de los 90”), sistemas de recomendación (el tan temido algoritmo de TikTok), o lectores de patentes que te mandan un parte por correo si pasaste por las pistas exclusivas de las micros.
En la frontera de los modelos de IA –los “cerebros” detrás de la revolución– están los grandes de Estados Unidos: OpenAI, Google, Anthropic, Meta, y xAI de Elon Musk; con enormes espaldas de miles de millones de dólares y todo el apoyo del gobierno, que lo ve como un activo estratégico. Tanto así que fueron impuestas restricciones de exportación al hardware que se usa para desarrollar y servir estos modelos.
Pero… ¿cuál es la maravilla de ese hardware tan especializado? Son las GPUs, o unidades de procesamiento gráfico, por sus siglas en inglés. ¿Gráfico? Bueno, sí pero no. Para mostrar gráficas 3D en una pantalla, tienes que hacer multiplicaciones para saber dónde dibujar cada cosa. Con el auge de los videojuegos y computación 3D en los 90, para generar gráficos 3D complejos, necesitabas hacer muchas multiplicaciones en paralelo, muchas veces por segundo, tanto que fue necesario desarrollar chips especializados: las GPU.
A mediados y fines de los 2000 el mundo se dio cuenta de que las GPUs no sólo servían para jugar Counter-Strike con más frames por segundo, sino también para todo tipo de tareas que requerían estos cálculos complejos: simulación de modelos climáticos, criptografía y criptoanálisis (y luego minado de criptomonedas… tema para otro día), análisis de grandes volúmenes de datos, bioinformática, redes neuronales, y un laaargo etcétera. La principal gracia para todas estas aplicaciones es que permiten realizar muchas operaciones en paralelo, con acceso muy rápido a los datos usando memoria especializada para hacerlo en paralelo, sin el cuello de botella de los procesadores y memoria de propósito general.
Entonces, a una startup en China que quiere meterse en el mundo de los modelos de IA, y que no tiene acceso a las mejores GPUs del mercado por las restricciones de exportación de EE.UU., no le queda otra opción que innovar. Necessity is the mother of invention, como dicen por ahí. Aprenden a trabajar con lo que tienen, y están obligados a re-pensar algunos de los fundamentos que se consideran obvios para los investigadores del mundo occidental.
Nuevas arquitecturas de modelos y estrategias de entrenamiento, y ya podemos ver un resultado notable: DeepSeek-R1. Un modelo comparable a lo mejor que occidente tiene para ofrecer, a una fracción del costo, y usando chips limitados. Y no se quedaron ahí: los modelos state of the art, en general, usan un método de aprendizaje llamado Reinforcement Learning, en que al modelo se le hace aprender a partir de sus errores, como cuando el profesor de matemáticas te mandaba a corregir los ejercicios que tuviste malos en la prueba global. Muchos creen que RL está limitado por cómo guía al modelo durante su aprendizaje, y muchos también creen que un modelo entrenado con RL autónomo puede degenerar en comportamientos indeseados.
Por eso los modelos estrella como o1 de OpenAI usan Reinforcement Learning with Human Feedback, donde son humanos quienes guían (parcialmente) el proceso de aprendizaje. Así prometen lograr resultados que son difíciles de evaluar de manera autónoma, y que dan más garantías sobre el comportamiento final del modelo, pues fue supervisado y corregido.
Pero los humanos son caros, trabajan 40 horas semanales, y se distraen mirando TikTok, así que DeepSeek-R1-Zero fue entrenado con RL sin supervisión humana. Resultó que tenía sus desventajas (e.g. mezcla idiomas y su razonamiento no es muy legible para humanos), pero demostró ser muy capaz. Y partiendo sobre una base de ejemplos deseables de razonamiento (generados con R1-Zero, arreglados por humanos), agregando incentivos para corregir lenguaje inconsistente, y otro par más de técnicas, es como llegamos a DeepSeek-R1, el flamante modelo anunciado hoy, que juega en las ligas mayores a la par con sus contrincantes occidentales.
DeepSeek y los mercados
Estos recientes anuncios de DeepSeek fueron los que hoy movieron a los mercados. Para ilustrarlo con números, entrenar el modelo DeepSeek-V3 (modelo de lenguaje base para su último modelo DeepSeek-R1) costó aproximadamente US$5,6 millones según los mismos autores, una fracción del costo de otros modelos líderes, cuyo entrenamiento asciende a decenas o incluso centenas de millones de dólares. Este avance podría redefinir el estándar de costos en la industria de la inteligencia artificial, y especialmente afectar al proveedor estrella de la actual revolución de la IA: Nvidia.
Así, este lunes, los inversionistas reaccionaron rápidamente, provocando caídas fuertes en la acción de Nvidia y moderadas en índices como el S&P 500 y el Nasdaq. Este nerviosismo se debe al reajuste del riesgo de competencia externa para el ecosistema de IA norteamericano. Además, estos movimientos han sembrado dudas sobre los recientes y masivos planes de inversión en infraestructura en EE.UU., especialmente después del ambicioso anuncio del presidente Trump sobre el proyecto "Stargate". En colaboración con OpenAI, Softbank y Oracle, este proyecto busca invertir 500 mil millones de dólares para potenciar el desarrollo de la IA en Estados Unidos.

¿Es el fin del "excepcionalismo" de la IA norteamericana?
Desde que la IA generativa se popularizó a finales de 2023, Estados Unidos ha lucido como el líder indiscutible, dejando a las otras potencias corriendo detrás, tratando de alcanzarlo. Por ejemplo, en Europa, un ecosistema tecnológico menos vibrante que Silicon Valley y un foco en regulación prematura han enfriado sus ambiciones, llevando a empresas punteras como la francesa Mistral a buscar asociarse con EE.UU.
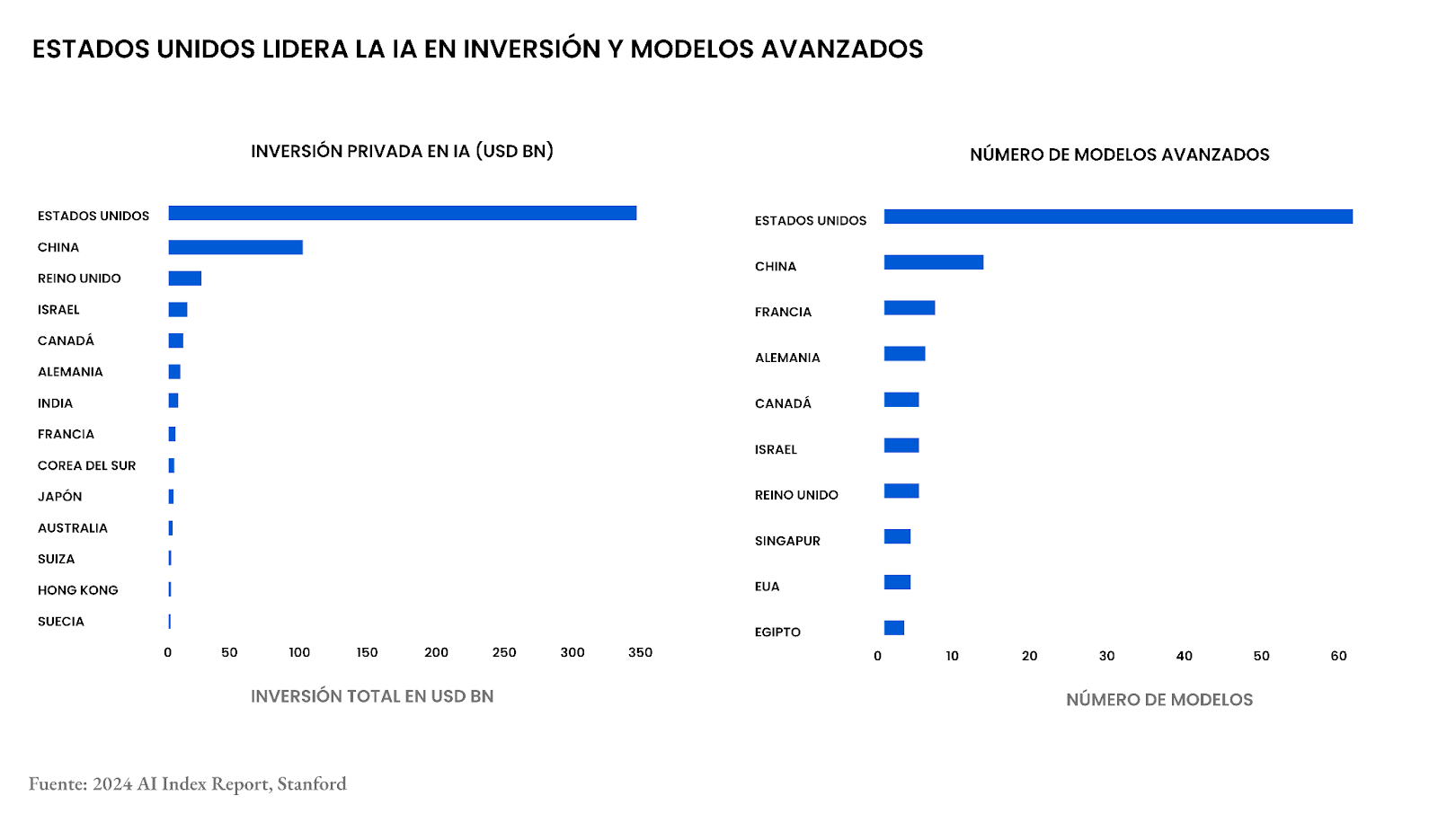
Pero, cuando volteamos a ver a China, la historia cambia de tono. Desde hace años China ha sido una potencia en áreas como la visión computacional y las patentes de IA. El único gran obstáculo que enfrenta para competir codo a codo con EE.UU. en el terreno de los grandes modelos de lenguaje como ChatGPT es el acceso a procesadores y GPUs de última generación.
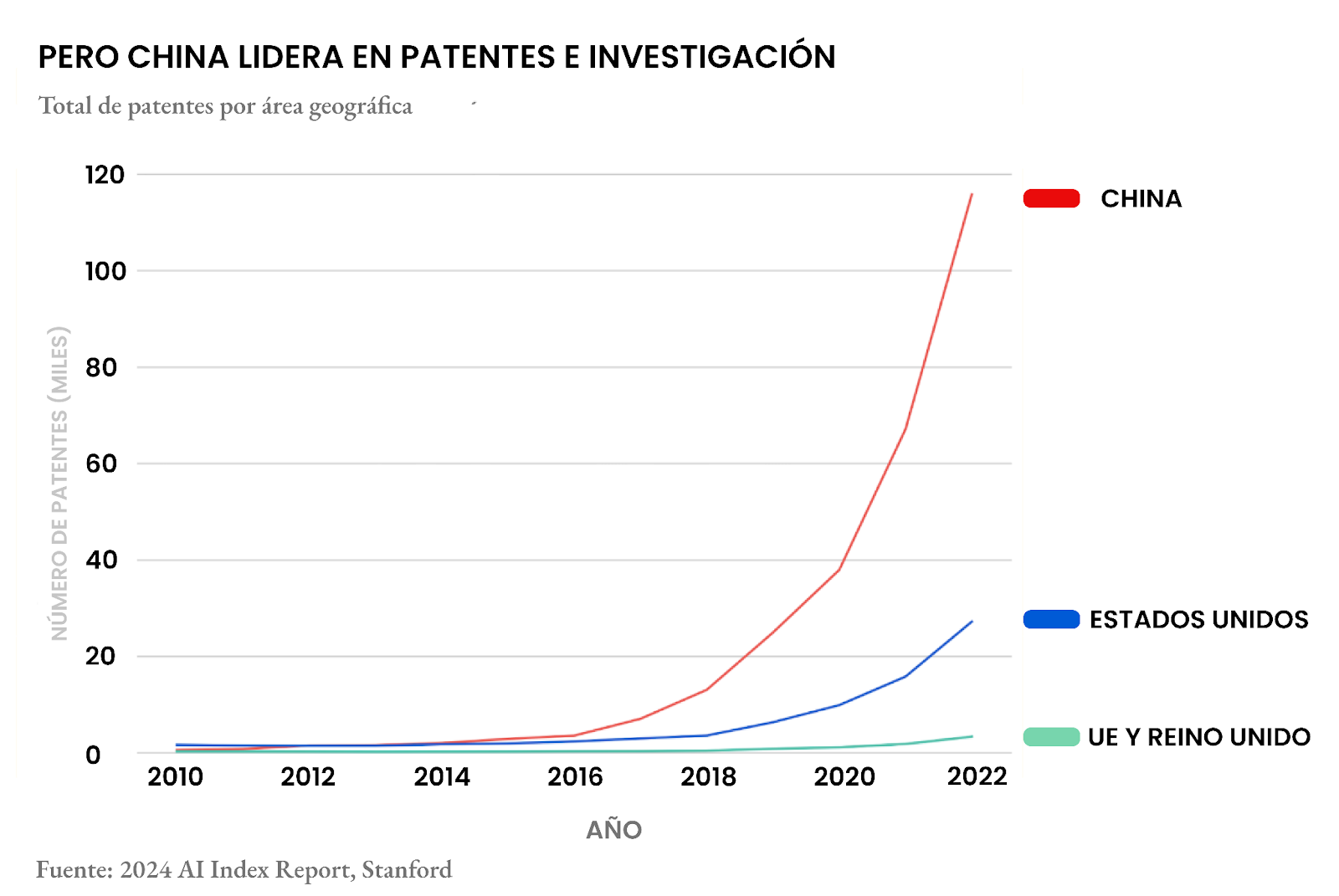
La llegada DeepSeek y sus últimos avances reafirman que China no solo está al nivel de Estados Unidos, sino que también, a pesar de las restricciones tecnológicas, ha logrado desarrollar modelos que rivalizan con los mejores de OpenAI y otros gigantes norteamericanos. Entonces queda la pregunta: si DeepSeek ha conseguido tanto con recursos limitados, ¿qué podría lograr con acceso a la infraestructura masiva de empresas como OpenAI o Google?
Estas noticias nos recuerdan que seguimos en medio de una explosión en el campo de la IA, donde nadie puede declararse aún ganador, y quedan muchos avances por ver. Además, la aceleración en los avances de una sola empresa impulsa a todo el ecosistema, especialmente cuando estos progresos son de código abierto, como en el caso de DeepSeek. Seguro que ingenieros de todo el mundo están con litros de café revisando y aprendiendo de estos avances, viendo cómo aplicarlos a sus propios modelos y empresas.
¿Más eficiencia, menos chips? El caso de la caída de NVIDIA
Este lunes, NVIDIA sintió un duro golpe en el mercado: sus acciones cayeron cerca de un 16.9% el lunes 27 de enero, evaporando más de 590,000 millones de dólares en capitalización de mercado, la mayor pérdida en la historia en tan solo un día.
La razón parece obvia: si los modelos de IA pueden ser igual de potentes con menos chips, entonces ya no necesitaremos tantos.
¿O sí? La paradoja de Jevons
La famosa paradoja de Jevons nos dice que aumentar la eficiencia de una tecnología no siempre reduce la demanda de sus insumos; a menudo, la aumenta.

Revisemos la historia para entender mejor. En el siglo XIX en Inglaterra, en pleno auge de la industrialización y con el sistema imperialista bajo presión, existía preocupación por las bajas reservas de carbón del imperio, que amenazaban su futuro desarrollo.
Ante esta problemática, muchos economistas y políticos se enfocaron en promover la innovación para aumentar la eficiencia de los motores a carbón, culminando en el avance del motor a vapor. Por el contrario, William Jevons argumentó que esta mayor eficiencia haría los motores más atractivos y aumentaría su demanda, superando el ahorro generado por la eficiencia y, por ende, aumentando el consumo total de carbón. Jevons tuvo razón; el uso de carbón no disminuyó, sino que se incrementó drásticamente, dando vida a la ahora famosa paradoja que lleva su nombre.
De forma similar, en el mundo de la IA generativa, modelos más eficientes podrían desencadenar un aumento en el consumo de GPUs, no una reducción; la existencia de mejores y más eficientes modelos prometen aumentar su consumo, porque abren casos de usos que hoy eran prohibitivos debido a su costo. En conclusión, si bien este tipo de noticias pueden reducir las expectativas de corto plazo de los ciclos de inversión en infraestructura de IA, en el largo plazo la existencia de mejores modelos y algoritmos sólo pueden aumentar su penetración la penetración de estos, apuntando a una mayor demanda final por chips y semiconductores.