Los Large Language Models (LLM) como ChatGPT necesitan un gran corpus –una colección de textos en formato electrónico– para existir.
Es gracias a su corpus que pueden resolver tareas como: “traduzca esto que le estoy presentando a este otro idioma”, “resúmame esto”, “respóndame tal pregunta”, “haga tal la operación”, etcétera.
Y los resultados han sido tan espectaculares que, en el último semestre, ha habido un hype planetario en torno a este avance de bleeding edge de la Inteligencia Artificial.
Pero como reitera hasta la saciedad Marvin Lanhenke en su curso de un mes llamado #30DAYSOFNLP para Medium: “Nada de esto se puede hacer si no se dispone de un corpus”.
¿Qué hay en el corpus de los LLM que hace que suenen inteligentes?
Los Large Language Models trabajan con centenares de miles de millones de palabras. Por ejemplo, el corpus de ChatGPT tiene 300 mil millones de palabras y el de Bard tiene 1,56 billones de palabras, cinco veces más grande que el de ChatGPT.
¿Y de dónde sacan esa información? En el caso de ChatGPT no se sabe, las fuentes están cubiertas de opacidad. Tal como la comunidad científica y/o académica de la Inteligencia Artificial viene denunciando hace meses, a diferencia de muchos otros avances en el área, OpenAI no ha revelado mucho de su mecanismo interno, ni desde su misma web, ni vía artículos publicados por arXiv, ni en GitHub, ni en Huggingface.
Nada.
Pero se podría hacer una apuesta acerca de la naturaleza del origen de los datos del corpus sobre el que ChatGPT trabaja.
La forma más obvia de armar un corpus, como los de ChatGPT o Bard es, evidentemente, capturar todo internet. Por ejemplo, existen servicios que te pasan el internet de agosto del 2023 y agarran todas las páginas web y también todo lo que está en las redes sociales: como Twitter, Facebook, o Instagram.
Ahora, la calidad de esa información es en general bastante pobre, porque uno puede meterse a un blog de gente troll, por ejemplo, que está escribiendo sobre Gran Hermano y descargar todos los textos. Pero en realidad, esta información no parece de mucha relevancia en términos factuales. Entonces, ¿qué se elige de internet cuando se arma un corpus?
Por suerte un texto del Washington Post abre la caja negra y nos muestra de qué suelen estar alimentados estos chatbots para sonar tan inteligentes.

Como muestra el gif, las tres áreas principales en los sets de datos de estos chatbots son: información sobre negocios e industrias (16%), tecnología (15%) y noticias y medios (13%). Y dentro de noticias y medios, lo que más destaca es bastante esperable: Wikipedia, The New York Times, la revista Times y The Guardian (y prácticamente nada de medios chilenos, olvídense del Diario Financiero, LUN o La Tercera). Es más, curiosamente solo hay textos de elmercuriodechile.com, una página apócrifa de El Mercurio y con una redacción bastante “imaginativa”.
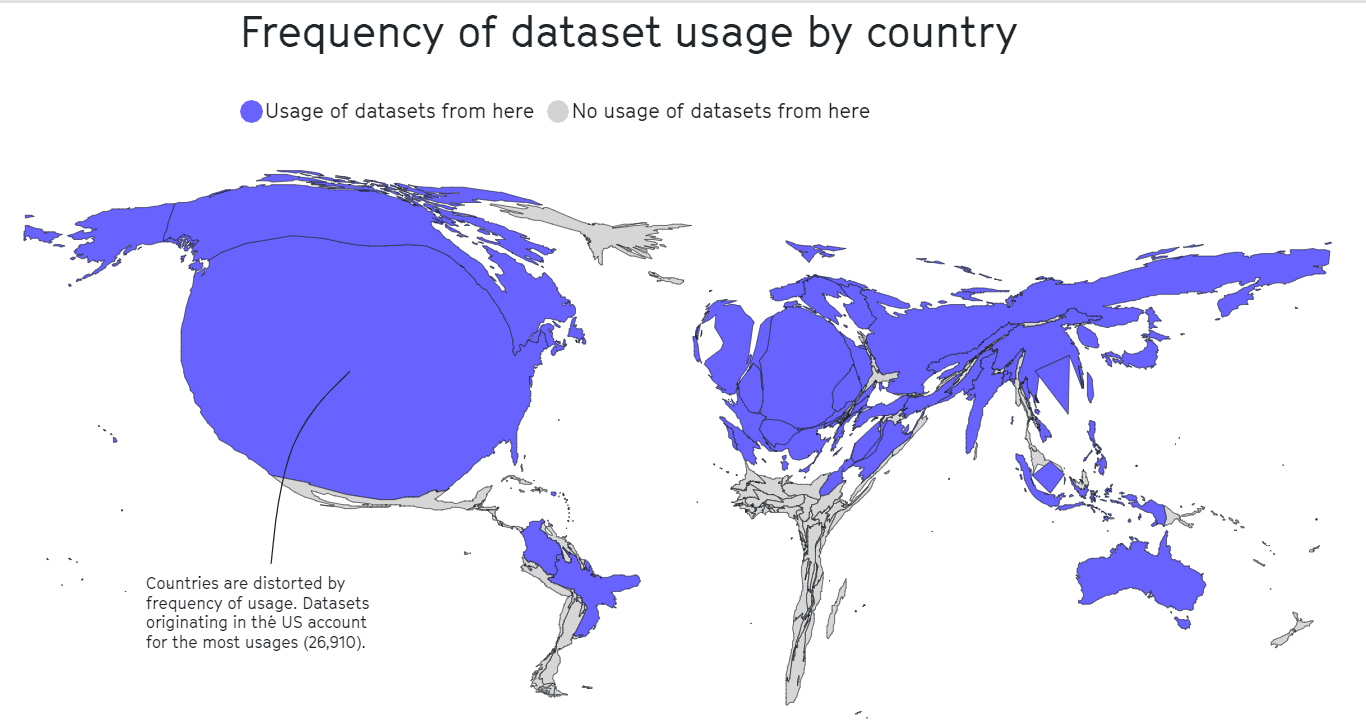
Pensemos que de los 300 mil millones de palabras que tiene ChatGPT, la información sobre Chile es súper pobre en general: los datos más robustos que tienen estos sistemas están alojados en Estados Unidos, Europa, Japón y Australia, pero no en países tercermundistas como Chile, que están en el Global South, como se dice por ahí. En la siguiente imagen se puede ver cómo en el Norte Global es donde están alojadas la mayoría de las bases de datos o corpora que alimentan a la IA contemporánea.
Y el problema, considerando lo poco diversos que son los corpus, es que servicios muy usados como ChatGPT no actualizan las bases de datos de sus modelos tan seguido. Es cosa de ver cómo el famoso chatbot de Open AI ya no se conecta a internet y sigue repitiendo que su conocimiento llega hasta el final del 2021.
Ted Chiang, el autor del cuento en el que se basa la película Arrival, escribió un artículo muy interesante para el New Yorker argumentando que, en el fondo, ChatGPT es como haberle sacado una foto a un pedazo de internet en una época específica, y luego comprimirla a un JPG un poco borroso. Al comprimir archivos –música, videos, textos, imágenes–, por lo general se pierden detalles o baja la calidad de la resolución. Pero lo que perdemos en calidad lo ganamos en acceso: como pesan menos, es más fácil llegar a ellos.
Esta “pérdida”, en el mundo de ChatGPT, sería perder la bibliografía exacta: la consume, la resume e interpreta hasta convertirla a “sus propias palabras”, pero ya no puede citar de forma exacta a las fuentes originales, igual como una imagen JPG no puede recuperar datos sobre el color o ciertos pixeles.
Entonces, ¿qué opciones hay más allá de estos famosos chatbots si queremos investigar de forma eficiente y amigable, con datos robustos y precisos que provengan de Chile? ¿Qué otros tipos de corpus y herramientas no han sido explorados o explotados todavía?
Un corpus nacional del tamaño de Wikipedia
La Universidad Diego Portales, después de haber participado en un concurso hace algunos años, logró hacerse de los archivos completos del diario La Nación entre 1917 y 2010.
Estimamos que este diario dispone de unos tres mil millones de palabras, de las que ya han sido procesadas para ser transformadas en un corpus 1,1 mil millones (disponibles en formato pdf en este link). O sea, La Nación es prácticamente del tamaño de la Wikipedia completa en inglés.
Este proyecto, liderado por Samuel Salgado, lo lleva a cabo CenFoto: un servicio de base de datos de la UDP que contiene principalmente los textos e imágenes de estos diarios. Para que te hagas una idea: les tomó al menos 5 años escanearlos.
Y no solo eso. Junto conmigo y el apoyo de un proyecto llamado Enlace de la UDP, hemos convertido todo el archivo de La Nación en un corpus.
Este proyecto, que nos ganamos en conjunto con CenFoto el año pasado, consistía en hacer más o menos lo mismo que hace Google Ngram: buscar tendencias de palabras y oraciones en libros escaneados.
Por ejemplo, en el Google Ngram Viewer buscas la palabra “Primera Guerra Mundial” y te dice cuándo apareció por primera vez o en qué medida iba apareciendo año a año.
En el caso de nuestro proyecto, este es un servicio que va a permitir buscar este tipo de tendencias dentro los diarios de Chile.
Hay un libro reciente (De Gruyter, 2022) sobre el tema del fortalecimiento de la búsqueda de datos –y, de paso, de los LLM– llamado Los diarios son el nuevo El Dorado para los historiadores (Digitised Newspapers – A New El Dorado for Historians?), donde se explica que un historiador antiguamente tenía que ir a buscar a las bibliotecas información de distintas cosas, revisando diario por diario, durante años, quemándose las pestañas; ahora con un sistema como este, tendría que poner simplemente una palabra que ande buscando y el sistema te arrojaría algo como: “Apareció en un diario de 1917, en otro del 1923 y tres veces en otro de 1925”, mostrándote directamente la operación y los resultados.
Y al mismo tiempo, se trata de una información que se puede cargar en un sistema de Large Language Model. Los diarios se han transformado en la nueva Piedra Filosofal de estos sistemas y son claves porque fueron nuestras “redes sociales” del SXIX y SXX: eran la tecnología de esa época para viralizar hechos e historias.
Solo como ejemplo de la gravitancia de los periódicos, es interesante lo que dice este artículo de Wired (Here's How Memes Went Viral — In the 1800s)[ruego disculpar lo extenso de la cita, pero a mi juicio, no tiene desperdicio]:
“LA HISTORIA LO TENÍA todo: un lugar exótico, una ingeniería impresionante, Napoleón Bonaparte. No es de extrañar que el relato de un viaje en un barco de fondo plano iluminado por una lámpara a través de las alcantarillas de París se volviera viral después de su publicación, el 23 de mayo de 1860.
Al menos 15 periódicos estadounidenses lo reimprimieron, exponiendo a decenas de miles de lectores a las húmedas maravillas del “espléndido sistema de alcantarillado” de la ciudad francesa.
Twitter es más rápido y HuffPo más sofisticado, pero la dinámica parasitaria de los medios en red era plenamente funcional en el siglo XIX. Como prueba, no busque más que el proyecto Infectious Texts, una colaboración de académicos de humanidades e informáticos.
El proyecto espera lanzarse a finales de mes. Cuando lo haga, los investigadores y el público podrán revisar textos ampliamente reimpresos identificados al extraer 41.829 números de 132 periódicos de la Biblioteca del Congreso. Si bien esta primera etapa se centra en textos anteriores a la Guerra Civil, el proyecto eventualmente incluirá los de finales del siglo XIX y se expandirá para incluir revistas y otras publicaciones, dice Ryan Cordell, profesor asistente de inglés en la Universidad Northeastern y líder del proyecto.
Algunas de las historias se imprimieron en 50 o más periódicos, cada uno con miles o decenas de miles de suscriptores. Los más populares probablemente fueron leídos por cientos de miles de personas, dice Cordell. La mayoría ha sido completamente olvidada. 'Casi ninguno de esos son textos que los académicos hayan estudiado, o que siquiera supieran que existían', dijo."
En el caso del corpus La Nación, se pueden hacer cosas similares. Por ejemplo, un colega estaba buscando los usos de la palabra “polera”, referida a la prenda de vestir ligera que cubre el torso. Él, buscando en otras bases de datos, había dado con un uso de aquella palabra en Persona Non Grata del Jorge Edwards de inicios de los setenta.
Buscando en el Corpus La Nación, di con que el término “polera” aparece ya en los años veinte del siglo XX en relación con el juego del “polo”, en modo de adjetivo.

El primer uso de “polera”, referido a una prenda de vestuario se aplica a “botas poleras”, en una publicidad.

Mientras que el primer uso referido a la prenda de ropa por la que se usa “polera” en la actualidad en Chile ocurre en concordancia con la palabra “blusa”.

De este modo, se puede ver que podría haber ocurrido en la historia de la lengua castellana chilena que “polera” se hubiera referido al principio a un tipo de bota del juego polo y derivó como adjetivo también para ciertos tipos de blusa.
Un segundo ejemplo es la búsqueda del desarrollo de un vocablo / palabra / término, el que corresponde a “Roto Quezada”, el famoso personaje mencionado en la tira cómica Condorito.
su primer uso en el Corpus La Nación es el siguiente:

Aunque no está todavía 100% operativo para uso público, acá está un ejemplo, cuando el corpus La Nación estaba cargado en el Ngram hasta 1959. Se buscó la palabra del nombre del lugar “Catapilco”.
Como se podría haber sospechado, la búsqueda de este término arroja que hay un peak de apariciones en 1957, particularmente por la irrupción del candidato presidencial de las elecciones para la presidencia del sexenio 1958–1964 del recordado “Cura de Catapilco”.
Pero ojo.
Hay un peak de apariciones incluso mayor en 1921.
Al buscar en el corpus del diario se encuentra un dato que llama la atención.

Este hecho fue cubierto a lo largo de varios días con muchas notas de prensa en La Nación.
Conclusiones
Disponer de una base de datos lingüística como el corpus La Nación es de suma utilidad para el estudio de la evolución de la lengua –en este caso castellana de Chile– y también para la documentación histórica.
Además, este tipo de fuentes tiene dos virtudes poco frecuentes: la primera es que se trata de un corpus monogénico, esto es, que proviene de una sola fuente homogénea, lo que le aporta mucha robustez temática y de enfoque a su indagación; la segunda, es que la fuente es diacrónica. Eso quiere decir que está ordenada cronológicamente en el tiempo, lo que permite seguir series temporales, hallar primeras ocurrencias de palabras (o de nombres propios) y así.
Por eso creo que esta herramienta, que se estrenará a fin de año, abrirá una puerta a “El Dorado de los lingüistas e historiadores”. Y es solo el comienzo. Crear chatbots con Inteligencia Artificial que incluyan fuentes históricas que provienen de nuestro país, como este corpus de La Nación, sería un segundo paso.