Generación sintética de escenarios económicos vía deep learning.
Motivación
¿Cuántas cosas podrían haber sucedido en el pasado que no sucedieron?
Como aquella vez que casi te caes en bicicleta camino al trabajo, pero por suerte te mantuviste de pie, o esa vez que te habías decidido por cambiar de departamento, pero a última hora cambiaste de parecer. La historia está repleta de eventos que perfectamente podrían haber sucedido, pero que finalmente nunca sucedieron.
Lo mismo sucede con los mercados y la economía en general.
Las empresas podrían haber tomado decisiones de inversión distintas, las acciones podrían haber rentado diferente, los bancos centrales podrían haber tomado otra trayectoria de tasas, etc. Es decir, existen muchos escenarios realistas de la evolución del mercado que nunca sucedieron, pero podrían haber sucedido.
Esto es un problema recurrente al modelar mercados financieros: Usar datos históricos como única fuente para estimar escenarios futuros presenta una visión obtusa de todos los posibles escenarios factibles. Es decir, el que no te hayas caído en bicicleta en el pasado no significa que no habrías podido caerte en el pasado, o que incluso podrías caerte en el futuro.
En un proceso robusto de construcción de portafolios este problema es relevante. Es necesario poseer escenarios de retornos de activos y factores macroeconómicos para calibrar la estimación de rentabilidades y riesgos de cola que se usan para el proceso de construcción de portafolios. Por lo que poder expandir la fuente de escenarios más allá de los datos históricos nos permite hacer portafolios más robustos y puedan considerar no solamente lo que sucedió, sino también lo que podría suceder.
Estado actual
Generar muestras nuevas no es algo novedoso en sí, desde simulaciones tipo Monte Carlo que se ha empleado usar datos generados para estimar el abanico de posibilidades futuras. Los tipos de modelos empleados pueden separarse en aquellos basados en la calibración distribuciones uni o multivariadas y aquellos modelos no paramétricos basados en construcción manual de escenarios. En el área de modelos paramétricos destaca el uso de Cópulas o distribuciones multivariadas para estimar la distribución conjunta de activos financieros. Si bien estos modelos poseen una robusta validez teórica, la naturaleza no lineal de los mercados han mostrado que estos modelos suelen quebrarse en escenarios de estrés, como lo fue en la estimación de correlaciones de los activos inmobiliarios durante la crisis Sub-Prime el 2008.
La otra forma de abordar este problema se ha basado en la generación manual de escenarios, usualmente conocido como stress tests, es decir, generar escenarios negativos que simulan alguna situación pasada (por ejemplo reproducir el efecto de la crisis DotCom en tu portafolio). Si bien este método se usa ampliamente, inclusive en la estimación de riesgo bancario, solo abarca escenarios extremos y describe la composición específica de los escenarios de riesgo del pasado.
En este contexto vamos a analizar cómo usando deep learning y en particular, las Redes Neuronales Generativas Adversarias o GANs podemos resolver las limitaciones de las metodologías tradicionales y generar escenarios de mercados realistas y flexibles que sean útiles para la construcción de portafolios.
GANs
¿Qué son los GANs?
Una GAN es una red neuronal que busca aprender los patrones presentes en los datos reales, para luego generar muestras sintéticas que, si bien nunca estuvieron presentes en los datos originales, preservan los patrones básicos que hacen que esta data sea creíble. Las primeras versiones de esta arquitectura de redes neuronales partieron el 2010 y, durante los últimos años, estas han generado enormes avances en la creación de contenido realista como imágenes, audio y video.

Este tipo de modelos también ha generado preocupación al ser la tecnología base para la generación de DeepFakes, que es contenido audiovisual sintético que puede replicar a algún político o celebridad promocionando información falsa o maliciosa.

¿Cómo funciona una GAN?
Las GANs se destacan porque en realidad operan como 2 redes neuronales compitiendo.
La primera red, usualmente llamada la generadora, busca con base a un input aleatorio (un vector de números aleatorios) generar el contenido objetivo lo más realista posible de manera sintética. Por otro lado, la segunda red, llamada detectora o discriminante, busca identificar entre una muestra mezclada de datos reales y sintéticos cuáles son los falsos y cuáles son los verdaderos.
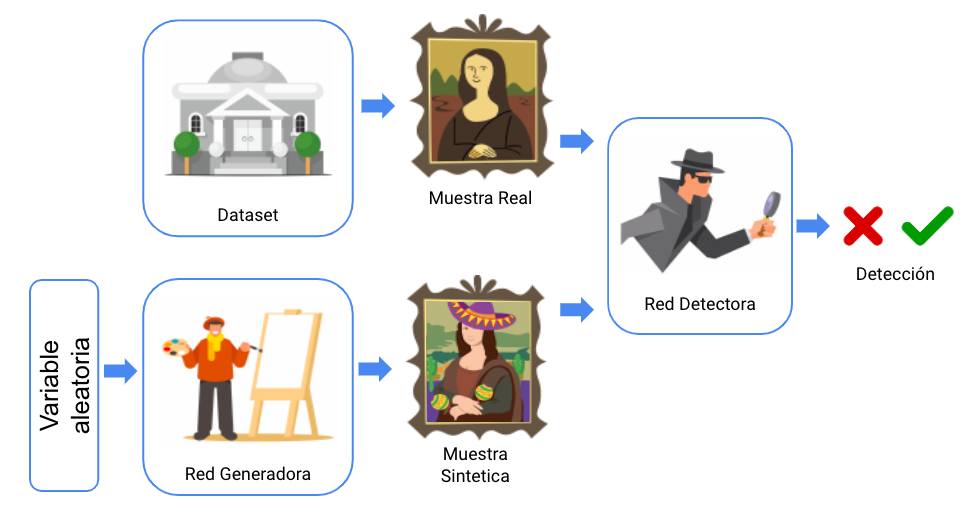
Las GANs, como cualquier otra red neuronal, van a optimizar sus parámetros de manera iterativa, donde la red detectora posee como función objetivo minimizar el porcentaje de muestras mal clasificadas, mientras que la red detectora busca minimizar el número de muestras sintéticas identificadas por la red detectora como falsas, es decir, ambas redes son adversarias y “compiten” progresivamente, mejorando la calidad del generador y del detector tras cada iteración de entrenamiento. (Si quieres saber más puedes revisar este blog)
En este contexto, nos propusimos usar modelos tipo GANs para producir “DeepFakes” de información financiera que repliquen las características generales de los mercados financieros vistos en el pasado para así exponer a nuestros modelos de construcción de portafolios a escenarios más diversos (pero realistas) y así conseguir portafolios más robustos.
Metodología
¿Qué necesitamos generar?
En nuestro caso, cada escenario corresponde a un vector con el retorno móvil de 12 meses de R activos.
¿Qué modelo utilizamos en específico?
Existen muchos tipos de arquitecturas de GANs para resolver distintos tipos de problemas, como la generación de imágenes, audio, texto, etc. Como se comentó anteriormente, el desarrollo de arquitecturas tipo GAN se ha enfocado en la generación de contenido audiovisual, donde sus arquitecturas base están especializadas para entrenarse sobre imágenes o series multidimensionales (espectrogramas para audio o series de matrices para video).
El caso particular de escenarios económicos es difícil de modelar simplemente como matrices de datos (tipo imágenes) o series multivariadas (tipo sonido o video) en el sentido de que la ubicación de cada elemento en la matriz o vector posee un significado relevante para una imagen o un sonido, mientras que el orden de las clases de activos a modelar es irrelevante.
En vista de las limitaciones vistas, proponemos utilizar una arquitectura llamada CT-GAN (Conditional Tabular Generarive Adversarial Network). La cual fue creada con el objetivo de reproducir datos tabulares, es decir, que cada muestra es una fila en una tabla de diversos atributos continuos y discretos.
¿Por qué Condicional?
La condicionalidad es una particularidad de esta arquitectura que lo hace muy útil para nuestro problema, ya que al momento de estimar el vector de atributos, cada elemento se estima como una muestra de la probabilidad condicional dado un “estado” dado una combinación de las variables discretas.
Formalmente, sea x la probabilidad de un escenario cualquiera y Di una variable discreta. Luego, para todo estado k podemos describir a x como:
x ℙ(escenario) = kDiℙ(escenario | Di=k) ℙ(Di=k)
Por ejemplo, imaginemos que queremos estimar una tabla de información de peso, altura y curso en un colegio.
Podríamos directamente intentar generar las 3 variables al unísono, pero las variables continuas tendrían que “entender” los saltos discretos que suceden en su distribución, ya que sabemos que alumnos de kínder siguen una distribución de peso y altura mucho menor que aquellos que cursan cuarto medio. En cambio, CT-GAN lo que hace primero es estimar la distribución de los estados discretos (los cursos), para luego estimar la distribución condicional multivariada de los atributos continuos, entregando una modelación más precisa para entender el comportamiento subyacente de estas variables.
En nuestro caso, la condicionalidad es útil porque existe amplia evidencia que el mercado posee comportamientos muy dispares dependiendo de diversos “estados” del mercado (“Risk-On”, “Risk-Off”, “Goldilocks”, “Flight to Quality” entre muchos otros son nombres típicos que el mercado suele darles a estos estados).
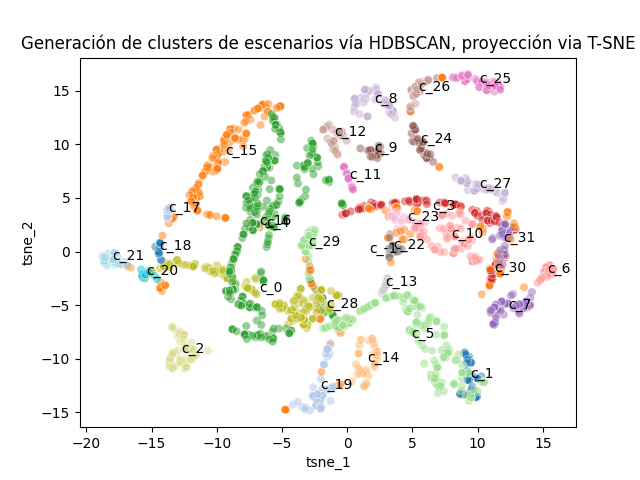
El problema es que estos estados no son observables a priori. Ante esto, una buena alternativa es utilizar una approach no supervisado. Empleamos una metodología basada en la generación de clústers de densidad:
- Proyectamos cada muestra en dos dimensiones. En este caso emplear modelos tipo PCA empleando un modelo no lineal (T-SNE), lo que permite generar una proyección estable que elimina el problema de hiperdimensionalidad al momento de estimar densidad.
- Creamos clústers sobre la proyección en 2D usando un modelo basado en densidad (HDBSCAN).
De esta manera, generamos un proceso donde las muestras con atributos similares definen clúster de “estados” del mercado.
En resumen, el proceso consiste en:
- Normalizar los atributos del dataset aplicando Z-score (así se evita dar preponderancia a una variable sobre el resto, ya que todas seguirán una distribución de rango similar)
- Generar clústers mediante HDBSCAN aplicado a la proyección 2D del dataset vía T-SNE.
- Entrenar CT-GAN utilizando el clúster como variable de estado.
- Con CT-GAN ya entrenado, generar una nueva muestra de datos sintéticos.
- Desnormalizar las variables utilizando la media y desviación estándar estimada inicialmente.
Implementación
Para este ejemplo, usaremos la rentabilidad de un grupo pequeño de índices accionarios y de renta fija (En la práctica empleamos un conjunto más amplio de activos).
Para entrenar emplearemos 3.000 muestras del periodo 2010-2022, con las cuales generamos otras 100.000 muestras sintéticas para comparar.
El proceso se escribió en Python utilizando las librerías de Sklearn y Hdbscan para la reducción de dimensionalidad y clusterización. Para la implementación de CTGAN se usó la implementación existente en la librería del Synthetic Data Vault del MIT Data Lab.
Los parámetros empleados fueron modificados levemente para una mejor convergencia (el T-SNE y HDBSCAN se realizó con parametrización por defecto, en la práctica realizamos un fine-tunning de estos):
Resultados
¿Cómo sabemos si funcionó?
No es una pregunta fácil, ¿Cómo sabemos que el generador es “realista pero novedoso”?. Lo que podemos hacer es usar criterios similares a los empleados en generación sintética de algo como imágenes de rostros. ¿Cómo decimos que un generador de caras es bueno? Fácil, primero, que las caras que generas se vean reales, es decir, repliquen los rasgos generales que definen una cara (dos ojos, la posición de la boca, las proporciones, etc.) pero que a su vez estas caras sean novedosas (no sean copias calcadas de una foto de Chuck Norris).
Ahora si, los resultados
Tomando estos principios, lo primero que buscamos es que se preserven las características básicas del dataset, es decir, sus distribuciones (tanto uni-variadas, como multi-variadas). Bajo este criterio, podemos ver en la matriz de distribuciones, donde comparamos las 3.000 muestras reales versus las 100.000 sintéticas, que tanto las distribuciones univariadas como el scatterplot de las distribuciones multivariadas muestran que la data sintética es capaz de asimilar las características principales de correlación y distribución presentes en los datos reales. El modelo “entiende” correctamente los pares de activos de más alta correlación a aquellos de menos, inclusive entre activos cuya correlación es más compleja (como entre US IG y EM Equities, donde se ven escenarios tanto de correlación positiva como negativa).

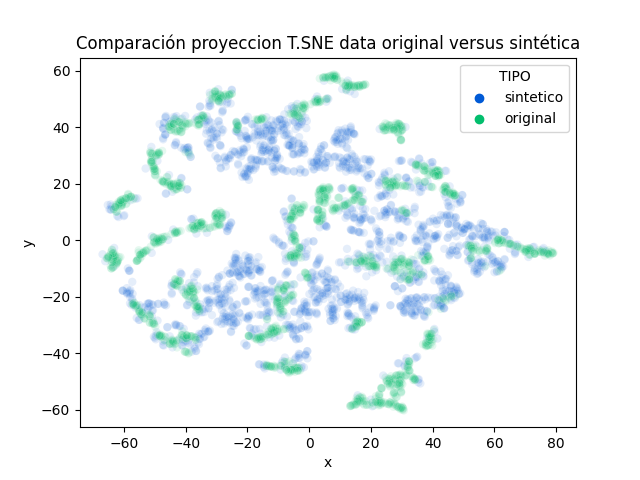
El segundo criterio, la originalidad del generador, es un poco más difícil de determinar. En nuestro caso, la revisión que generamos es que el dataset sintético, al ser proyectado en 2D vía TSNE, encontramos que el dataset sintético rellene espacios no cubiertos por el dataset original. Es decir, el modelo puede generar cosas diferentes a las ya existentes, pero respetando las reglas generales de su comportamiento.
Conclusión
Es posible usar herramientas como GANs y CTGANs para expandir los datasets que usualmente se emplean para el análisis financiero y construcción de portafolios, generando nuevos escenarios que nunca existieron, pero pudiesen haber existido al seguir entender y replicar los patrones básicos presentes transversalmente en el mercado.
Si bien estas herramientas son útiles para el problema particular de la optimización de portafolios, vemos mucho más potencial en la generación sintética de escenarios, al robustecer la estimación de retornos y riesgos.